

בטח נתקלתם פעם בקופסאות המוזרות האלה שכתוב בתוכן "אני לא רובוט" ותהיתם לעצמכם אם פספסתם משהו ולמה מאשימים אתכם שהיותכם רובוטים כל עוד לא הוכחה אנושיותכם. אבל האמת היא שאלה לא היו גוגל שהתחילו עם זה. כדי להבין את הנושא יותר לעומק, אנחנו צריכים להתחיל עם הגרסאות המוקדמות יותר של ה- Captcha.
מה זה בכלל Captcha?
מדובר בתהליך בו בדרך כלל המשתמשים מתבקשים להעתיק אותיות וספרות שמופיעות בתמונות מעוותות לתוך תיבת טקסט צמודה, במטרה להוכיח שהם בני אנוש ולא רובוטים. זה מוכר לנו בעיקר ממילוי טפסים או קניות אונליין ונראה בערך כך:
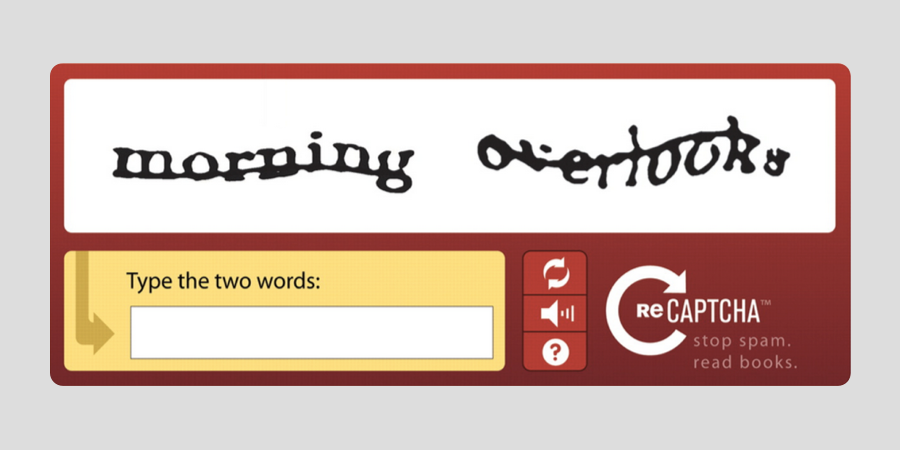
ה- Captcha הומצא בשנת 2003 על ידי Luise Vav Ahn וצוות המחקר שלו באוניברסיטת CMU שבפנסילבניה, במטרה למנוע spam על כל צורתיו וגווניו באינטרנט.
ומאיפה השם הזה, שאלתם? לא מדובר במילת קסם או בכינוי מאיזשהו ספר או סרט, אלא פשוט בראשי תיבות למילים: Completely Automated Public Turing test to tell Computers and Humans Apart.
Captcha יותר קל, נכון? היום אולי כן. אבל בעבר זה היה רכיב שגרר המון ביקורת, בעיקר מאנשים בעלי מוגבלויות מסויימות שמנעו מהם להשלים את ההליך, ובאופן כללי – זה לא בדיוק תהליך ידידותי למשתמש.
מאז ועד היום
בתחילת הדרך, המשתמשים היו צריכים להקליד אותיות או ספרות רנדומליות, ובהמשך החליטו להשתכלל ולנצל טוב יותר את השטח שאותו רכיב תופס. בגלגול הבא של ה- Captcha התחילו לסרוק ספרים ולבקש ממשתמשים להעתיק מילים חסרות הקשר שהמחשב לא מבין. ברגע שמספיק אנשים כתבו את אותו הפירוש למילים שהוצגו בפניהם, המילים הללו אושרו והועלו לבסיס נתונים ענק של ספרים אינטרנטיים. זה כבר הפך את התהליך על פיו ואת שמו של התהליך ל- Re Captcha. הסלוגן של הפרויקט הזה היה: "Stop spam, read books" ובאותם ימים פתרו כ- 100 מליון Re Captcha ביום (רק כדי להבהיר כמה זה הרבה – זה שווה ערך ל- 2.5 מליון ספרים בשנה).
ואיך כל זה קשור לגוגל?
גוגל רכשו את ה- Captcha בשנת 2009, והפכו את כל הארכיונים של הניו יורק טיימס ואת כל ה- Google books לדיגיטליים. כשנגמרו להם המילים (פשוטו כמשמעו), הם התחילו לתת למשתמשים לפענח מספרי בתים מ- Google streets view ולקודד גם אותם כדי להשתמש בהם במפות של גוגל.
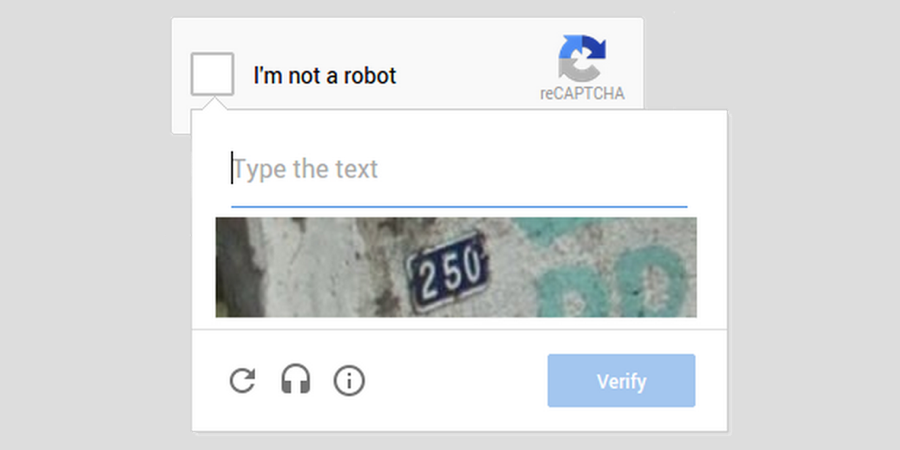
למרות השכלולים, עדיין היו ל- Captcha כמה בעיות
- נגישות – זה הקשה על לקויי ראיה, למשל, למלא טפסים אונליין, לעשות קניות באינטרנט וכן הלאה. הפתרון לזה היה אודיו של ה- Re Captcha. זה אכן פתרון הגיוני אבל זה לא בדיוק נשמע ברור, וכעת אנשים עם בעיות שמיעה עלולים להתקשות, כמו גם אנשים שסובלים מדיסלקציה לסוגיה.
- הונאות – השירותים למעשה שלחו את ה- Captcha של משתמשים ושלחו אותם לחוות Captcha במדינות עולם שלישי, בהן הועסקו עובדים שתפקידם היה לפתור את ה- Captcha שלכם ולשלוח אותה בחזרה.
- בסופו של דבר, בוטים התחילו לפתח יכולות לפתור את ה- Captcha ובכך התכלית כמובן איבדה מערכה. מה שהוביל למסקנה המתבקשת להפוך את זה לקשה יותר לפתרון. המחשבה הזו, שעלתה לרבים מאיתנו בתסכול רב, הובילה לתוספות של שיבושים, עיוותים והסחות לתמונות של האותיות. גם את האתגרים הקשים הללו בוטים החלו לפצח.
תפנית בעלילה : המחשבים של גוגל יודעים יותר מבני אדם (תודו שהופתעתם)
כנסיון לתת מענה על כל הבעיות הללו, גוגל החליטו לבצע מחקר ומצאו שבני אנוש פותרים נכונה את ה-Captcha רק ב- 33% מהמקרים, לעומת הטכנולוגיות המתקדמות של גוגל שכבר היו מסוגלות לפתור את זה ב- 99.8% מהמקרים. התגלית המרעישה הזו הובילה לתפנית חדה בנושא.
ה-Captcha כפי שאנו מכירים היום
גוגל החליטו להיפטר מתצוגת ה-Captcha המייגעת והמתסכלת והציגו לעולם את זה:
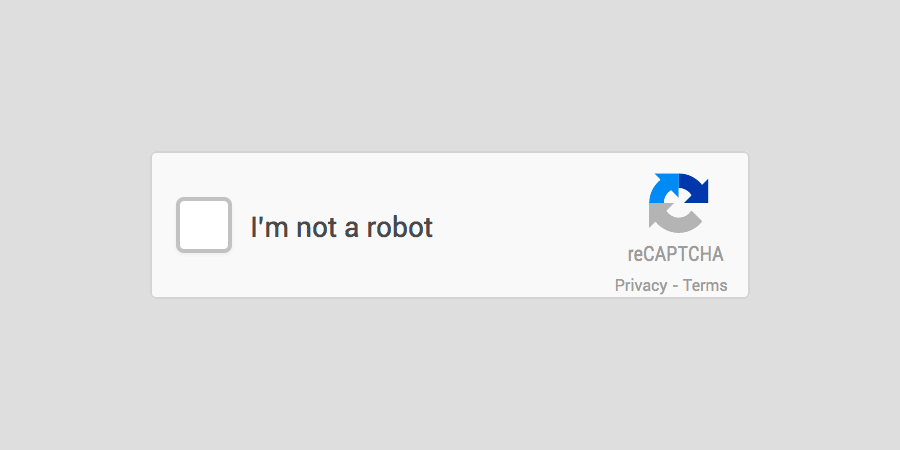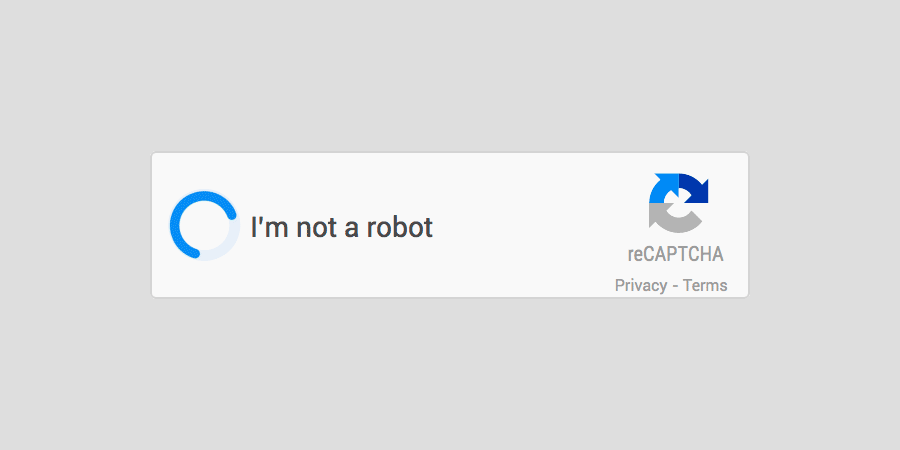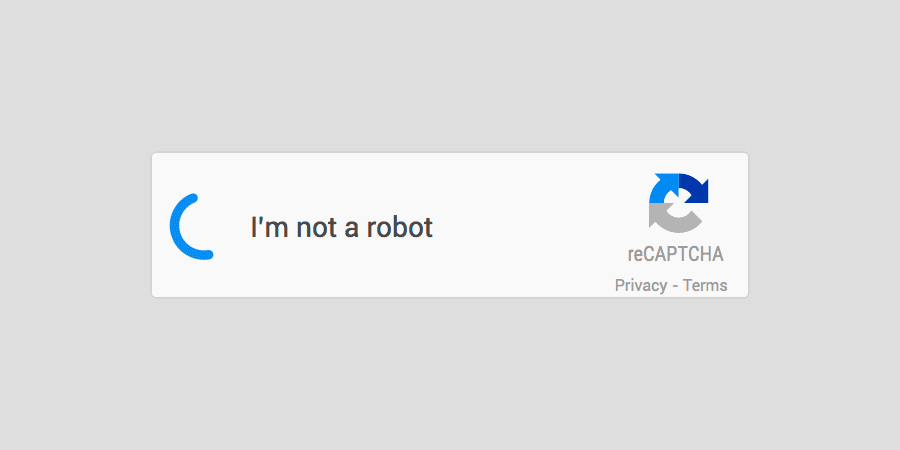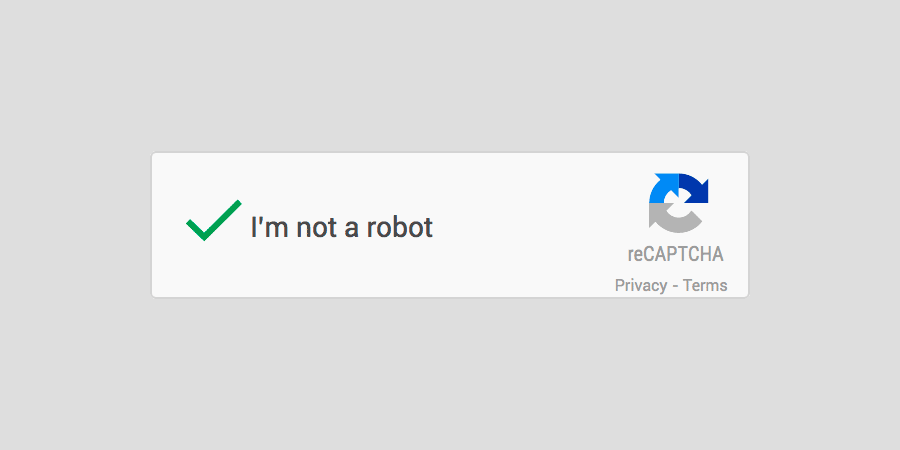
No Captcha Re Captcha
ואיך זה עובד?
כשלוחצים על זה, נשלחת לגוגל בקשת http שמכילה כל מיני פיסות מידע שימושיות כגון: כתובת ה- IP שלכם, המדינה ממנה אתם גולשים, הזמן המדוייק בו נשלחה הבקשה (time stemp), מידע מהדפדפן שלכם על האופן שבו אתם גולשים ומזיזים את העכבר לתוך גבולות הצ'ק בוקס, איך אתם גוללים לפני שאתם מקליקים על הצ'ק בוקס ועוד משתנים רלוונטיים שגוגל שומרת בסוד.
כל הקריטריונים הללו, שכאמור, מגיעים לגוגל עם לחיצה על הצ'ק בוקס, עוברים עיבוד במנוע חישוב סיכונים בגוגל, שרוב הזמן יודע להביע על ההבדל בין אדם לבוט.
נכון, רוב הזמן. אז מה קורה כשהמנוע עדיין לא בטוח, אתם שואלים? במצבים כאלה המשתמשים מתבקשים לבצע אתגר נוסף, שמשלב בחירת תמונות.
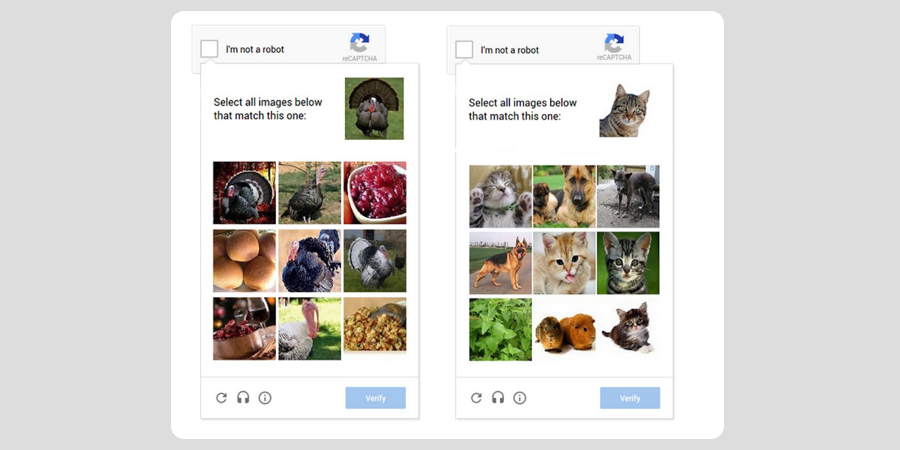
אם בשלב השני אתם אכן מוכיחים את אנושיותכם, תוכלו לעבור את זה בקלות גם בפעם הבאה 🙂
אהבתם את הפוסט? אולי תאהבו גם את עמוד הפייסבוק שלנו, אנחנו מעלים טיפים יומיים על נושאים שמרגשים אותנו.
ממש תודה על ההסבר הברור!!!
אולי אפשר לצרף גם את הקוד???
זה יעזור מאד!